
Friday, March 4, 2011

~~how to make money from heartbeat~~
huhu..da lame blog ni terbiar lesu..xpena diupdate pun since lepas subject comp tu..sangat2 malas..but now, tertarik plak dengan heartbeat ni..so kat cni nk ajar cane nk pasang iklan ni..
1. kena klik dkt iklan bawah ni
2.lepas tu, tekan dekat heartbeat yang da dibulatkn tu

3.then, tekan create account

4.isi semua yang dia nak pastu click i agree n then continue

5.then. join hb

6.pastu, klik on9 application

7.lepas da isi sume, tekan get code utk paste banner tu dekat blog


pastu da pasang dengan jayany=)))
~~~seLamaT meNcuba!!~~~
Tuesday, October 19, 2010

~~INTRODUCTION OF XML~~
Extensible Markup Language (XML) is a set of rules for encoding documents in machine-readable form.
XML's design goals emphasize simplicity, generality, and usability over the Internet.[6] It is a textual data format with strong support via Unicode for the languages of the world. Although the design of XML focuses on documents, it is widely used for the representation of arbitrary data structures, for example in web services.
~~THE DIFFERENCE BETWEEN XML AND HTML~~
- xml is not a replacement for html
- xml was designed to transport data while html was designed to display data
- html is about displaying information, while xml is about carrying information
XML TABLE
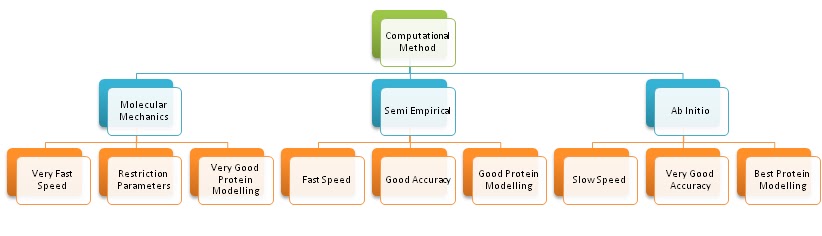
| Molecular Mechanics | Semi Empirical | Ab Initio |
|---|---|---|
| Very Fast Speed | Fast Speed | Slow Speed |
| Restriction Parameters | Good Accuracy | Very Good Accuracy |
| Very Good Protein Modelling | Good Protein Modelling | Best Protein Modelling |
Sunday, October 17, 2010
~~pDb~~

DO YOU KNOW WHAT IS PDB??
PDB IS A Protein Data Bank (PDB) that is for a repository for the 3-D structural data of large biological molecules, such as proteins and nucleic acids. (See also crystallographic database). The data, typically obtained by X-ray crystallography or NMR spectroscopy and submitted by Biologist and biochemists from around the world, are freely accessible on the internet. The PDB is overseen by an organization called the Worldwide Protein Data Bank, wwPDB. The PDB is a key resource in areas of structural biology, such as structural genomics. Most major scientific journals, and some funding agencies, such as the NIH in the USA, now require scientists to submit their structure data to the PDB. If the contents of the PDB are thought of as primary data, then there are hundreds of derived (i.e., secondary) databases that categorize the data differently. For example, both SCOP and CATH categorize structures according to type of structure and assumed evolutionary relations; GO categorize structures based on genes.
HISTORY OF PDB.
The PDB originated as a grassroots effort. In 1971, Walter Hamilton of the Brookhaven National Laboratory agreed to set up the data bank at Brookhaven. Upon Hamilton's death in 1973, Tom Koeztle took over direction of the PDB. In January 1994, Joel Sussman was appointed head of the PDB. In October 1998,[2] the PDB was transferred to the Research Collaboratory for Structural Bioinformatics (RCSB); the transfer was completed in June 1999. The new director was Helen M. Berman of Rutgers University (one of the member institutions of the RCSB).[3] In 2003, with the formation of the wwPDB, the PDB became an international organization. Each of the four members of wwPDB can act as deposition, data processing and distribution centers for PDB data. The data processing refers to the fact that wwPDB staff review and annotates each submitted entry. The data are then automatically checked for plausibility. (The source code for this validation software has been made available to the public at no charge.
CONTENT
| Experimental Method | Proteins | Nucleic Acids | Protein/Nucleic Acid complexes | Other | Total |
|---|---|---|---|---|---|
| X-ray diffraction | 55480 | 1231 | 2605 | 17 | 59333 |
| NMR | 7512 | 925 | 162 | 7 | 8606 |
| Electron microscopy | 214 | 17 | 77 | 0 | 308 |
| Hybrid | 24 | 1 | 1 | 1 | 27 |
| Other | 126 | 4 | 4 | 13 | 147 |
| Total: | 63356 | 2178 | 2849 | 38 | 68421 |
-
- 48,715 structures in the PDB have a structure factor file.
- 5,901 structures have an NMR restraint file.
These data show that most structures are determined by X-ray diffraction, but about 15% of structures are now determined by protein NMR. When using X-ray diffraction, approximations of the coordinates of the atoms of the protein are obtained, whereas estimations of the distances between pairs of atoms of the protein are found through NMR experiments. Therefore, the final conformation of the protein is obtained, in the latter case, by solving a distance geometry problem. A few proteins are determined by cryo-electron microscopy. (Clicking on the numbers in the original table will bring up examples of structures determined by that method.)
The significance of the structure factor files, mentioned above, is that, for PDB structures determined by X-ray diffraction that have a structure file, the electron density map may be viewed. The data of such structures is stored on the "electron density server", where the electron maps can be viewed.
In the past the number of structures in the PDB has grown at an approximately exponential rate. However, since 2007 the rate of accumulation of new proteins seems to have plateaued, with 7263 proteins added in 2007, 7073 in 2008, and 7448 in 2009.
PDB DATA
Information required includes
- coordinates of all atoms
- chemical description of the various molecules in the crystal
- experimental information about the structure
- structural description of the biological molecule
Tuesday, October 12, 2010
sMilEs=)

when people heard about smiles, they must refer to someone who are smiles to others. however, smiles that i want to share with you is something different from that.
do you know that Smiles is refer to simplified molecular input line entry specification.
The simplified molecular input line entry specification or SMILES is a specification for unambiguously describing the structure of chemical molecules using short ASCII strings. SMILES strings can be imported by most molecule editors for conversion back into two-dimensional drawings or three-dimensional models of the molecules.
The original SMILES specification was developed by Arthur Weininger and David Weininger in the late 1980s. It has since been modified and extended by others, most notably by Daylight Chemical Information Systems Inc. In 2007, an open standard called "OpenSMILES" was developed by the Blue Obelisk open-source chemistry community. Other 'linear' notations include the Wiswesser Line Notation (WLN), ROSDAL and SLN (Tripos Inc).
~~smiles bond~~
| smiles bond | figure |
|---|---|
| single | - |
| double | = |
| Triple | # |
| aromatic | : |
~~smiles symbols~~
- string of alphanumeric character and certain punctuation symbols
- terminates at the first space encountered when read left to right
- the organic subset: B, C, N, O, P, S, F, Cl, Br, I
- specify attached hydrogens and charges in square brackets
- number of attached hydrogens is the symbol H followed by optional digit
Monday, October 11, 2010
#Chemsketch#
- Draw and view structures in 2D, or render in 3D to view from any angle
- Draw reactions and reaction schemes, and calculate reactant quantities
- Generate structures from InChI and SMILES strings
- Generate IUPAC systematic names for molecules of up to 50 atoms and 3 ring structures
- Predict logP for individual structure
- Search for structures in the built-in dictionary of over 165,000 systematic, trivial, and trade name
~~Benefits~~
- Visualize chemical structures in 2D or 3D to gain more insight into spatial configurations, and relationships to molecular properties
- Create professional reports, working with structures, text, and graphics simultaneously
 how to sketch the dna molecules in the chemsketch?
how to sketch the dna molecules in the chemsketch?
1
chose draw
2 Click Polyline
3 Drag vertically down from the starting point of the curve to stretch the control line
4 Release the mouse button.
5 Move the mouse to the right to draw the curve
6 Drag vertically down to stretch the control lines. By changing the length of the control lines you can modify the form of the curve.
7 Release the mouse button and right-click twice to finish drawing the curve and to switch to the Select/Move/Resize tool
8 Place the mouse pointer over the selected curve and, while holding down CTRL+SHIFT, drag it down (holding down CTRL while dragging leaves behind an instant copy of the object and holding down SHIFT forces the object to move strictly vertically or horizontally).
9 Select both curves by dragging the selection rectangle around them or by clicking on each of the curves while holding down SHIFT, then from the Object menu, choose Connect Lines to connect the right ends of the curves
10 Click Edit Nodes
11 Click Connect Vertices
12 click Convert to Line
13 Right-click to leave the Edit Nodes mode and to switch to the Select/Move/Resize tool